I am a final-year Ph.D. Candidate at MIT EECS, advised by Prof. Song Han. I also closely work with Prof. Fred Chong at the EPiQC center, Prof. Anantha Chandrakasan (MIT) and Prof. David Pan (UT Austin). I received my B.S with honors from Fudan University. My research is supported by Qualcomm Innovation Fellowship, Baidu Fellowship, and Unitary Fund. I am the co-founder of the QuCS “Quantum Computer Systems” Forum.
I am on academic job market this year, please reach out for any opportunities!
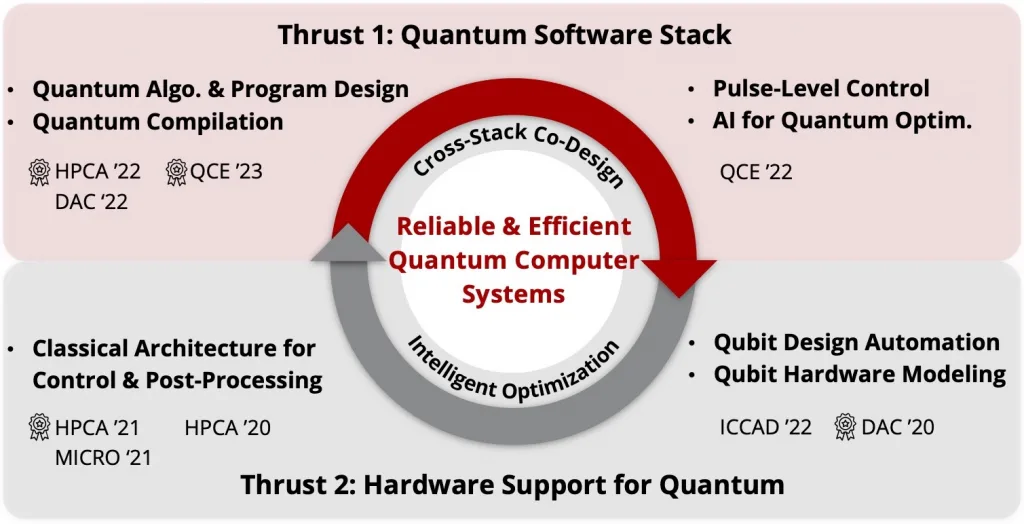
My research area is the intersection of Quantum Computing, Computer Architecture and Machine Learning. My research aims to build software stack and hardware support for quantum computing with AI-Assisted cross-stack co-design methodology to bridge quantum applications to available quantum devices.
- Cross-stack algorithm architecture hardware co-design for practical quantum computing
- AI for quantum program, compiler, hardware design
- Efficient algorithm-hardware co-design for Transformer models
I commit 1~2 hours every week to provide guidance, suggestions, and/or mentorships for students from underrepresented groups or whoever is in need. Please fill in this form if you are interested.
News
- 2024.03, “FPQA-C: A Compilation Framework for Field Programmable Qubit Array” accepted to ISCA 2024.
- 2024.02, selected as Rising Star of ISSCC 2024.
- 2024.02, “Q-Pilot: Field Programmable Quantum Array Compilation with Flying Ancillas” accepted to DAC 2024.
- 2024.01, “NAPA: Intermediate-level Variational Native-pulse Ansatz for Variational Quantum Algorithms” accepted to TCAD.
- 2023.11, Our team won the 1st place in ICCAD Quantum Drug Discovery Challenges
- 2023.10, “DOTA: Photonics Transformer Accelerator” accepted to HPCA 2024.
- 2023.09, Best Paper Award at QCE 2023.
- 2023.09, attended the ML and Systems rising star workshop.
- 2023.07, 3 papers accepted to QCE 2023.
- 2023.07, 1 paper accepted to QSEEC 2023.
- 2023.07, Best Demo Award at DAC 2023 university demo.
Publications (full list)
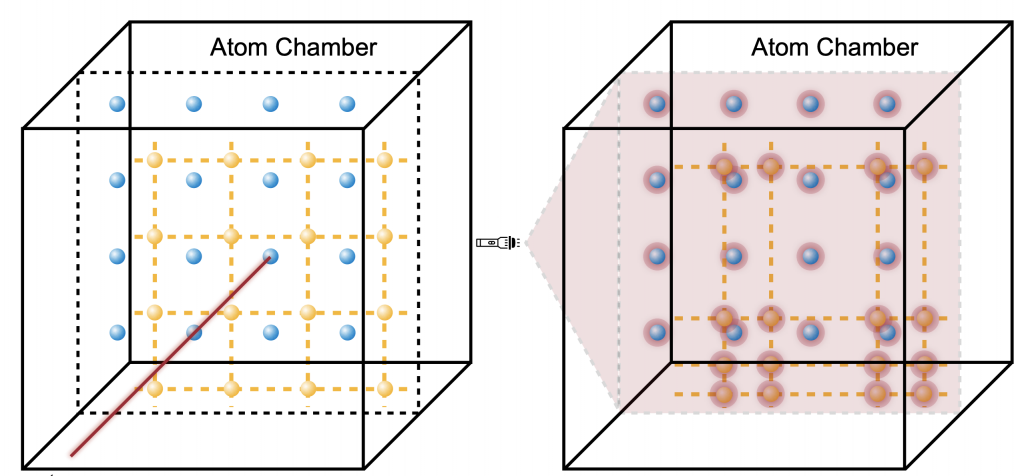
ISCA’24 FPQA-C: A Compilation Framework for Field Programmable Qubit Array
Hanrui Wang, Pengyu Liu, Bochen Tan, Yilian Liu, Jiaqi Gu, David Z. Pan, Jason Cong, Umut Acar, Song Han
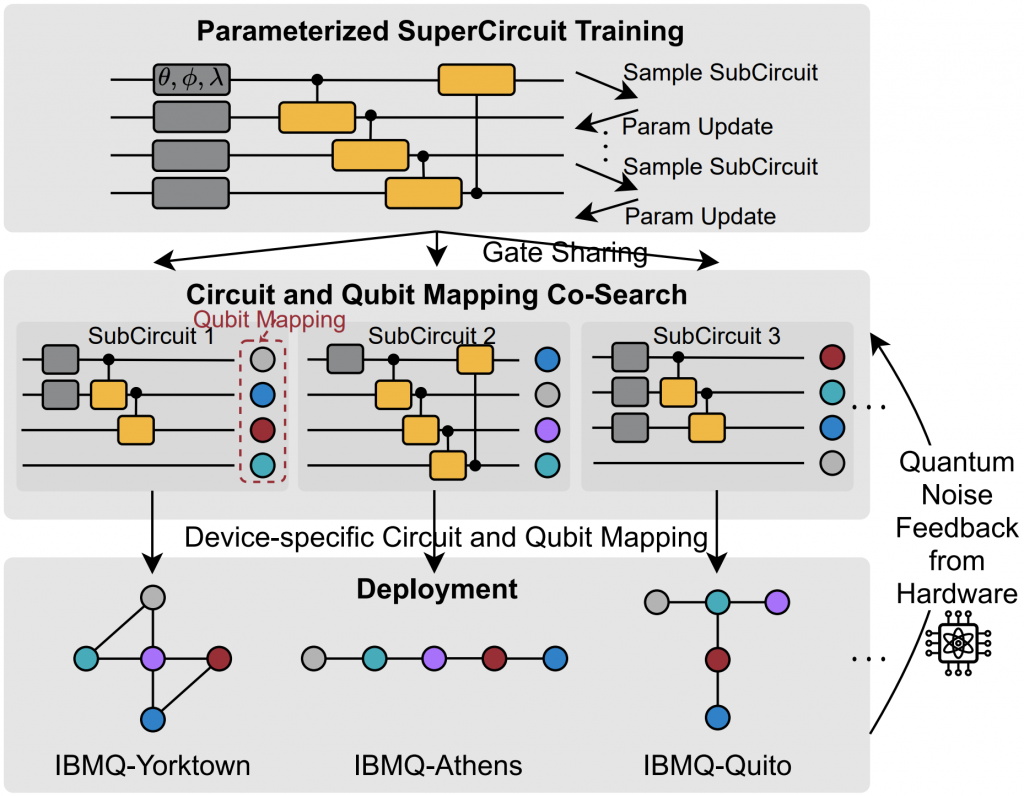
HPCA’22 QuantumNAS: Noise-Adaptive Search for Robust Quantum Circuits
Hanrui Wang, Yongshan Ding, Jiaqi Gu, Zirui Li, Yujun Lin, David Z. Pan, Fred Chong, Song Han
1st Place ACM Student Research Competition
Best Poster Award at NSF Athena AI Institute
Paper / Poster / Code / Project Page
DAC’24 Q-Pilot: Field Programmable Qubit Array Compilation with Flying Ancillas
Hanrui Wang, Bochen Tan, Pengyu Liu, Yilian Liu, Jiaqi Gu, Jason Cong, Song Han
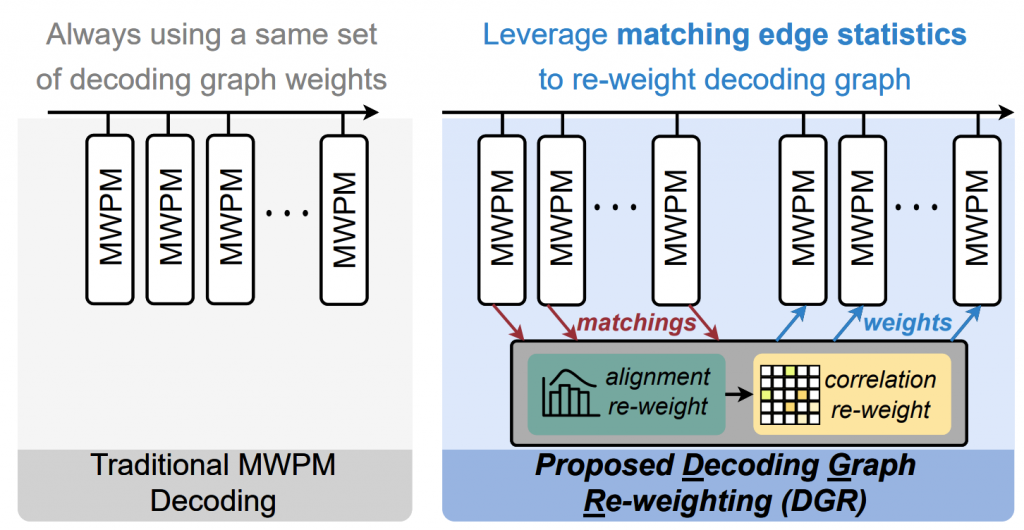
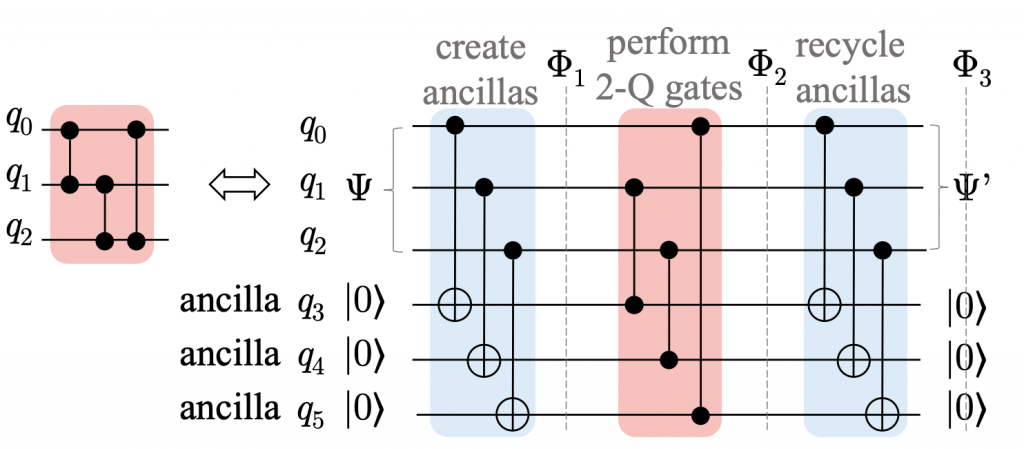
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Hanrui Wang, Pengyu Liu, Yilian Liu, Jiaqi Gu, Jonathan Baker, Frederic T. Chong, Song Han
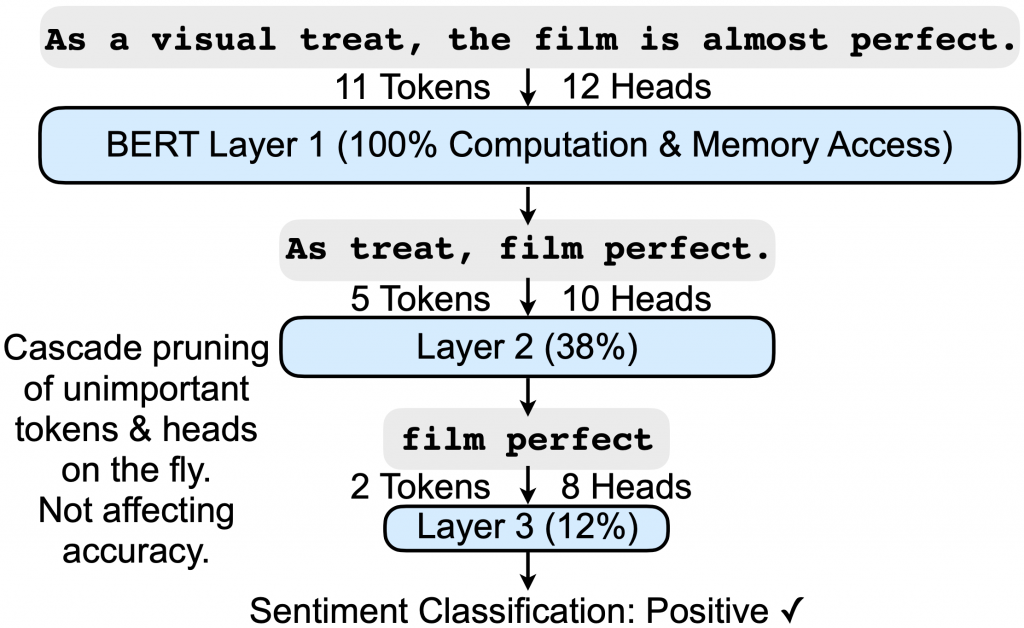
HPCA’21 SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning
Hanrui Wang, Zhekai Zhang, Song Han
Best Demo Award at DAC University Demo
Paper / Slides / Intro Video / Short Video / Project Page
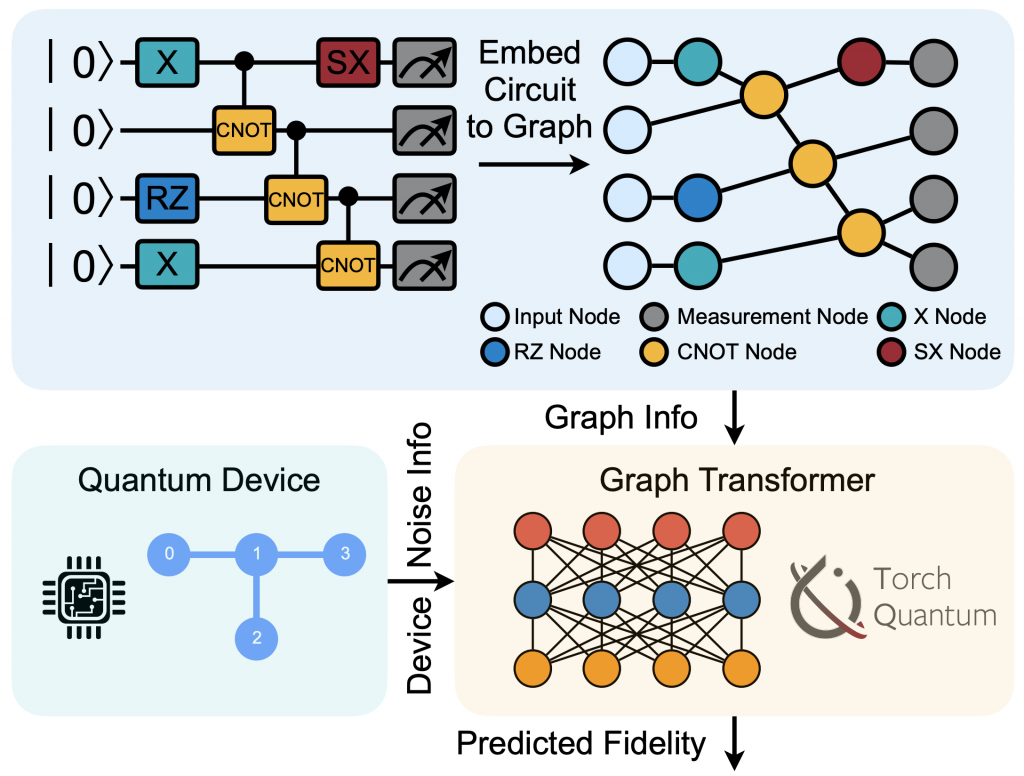
ICCAD’22 QuEst: Graph Transformer for Quantum Circuit Reliability Prediction (TorchQuantum Case Study for Robust Quantum Circuits)
Hanrui Wang, Pengyu Liu, Jinglei Cheng, Zhiding Liang, Jiaqi Gu, Zirui Li, Yongshan Ding, Weiwen Jiang, Yiyu Shi, Xuehai Qian, David Z. Pan, Frederic T. Chong, Song Han
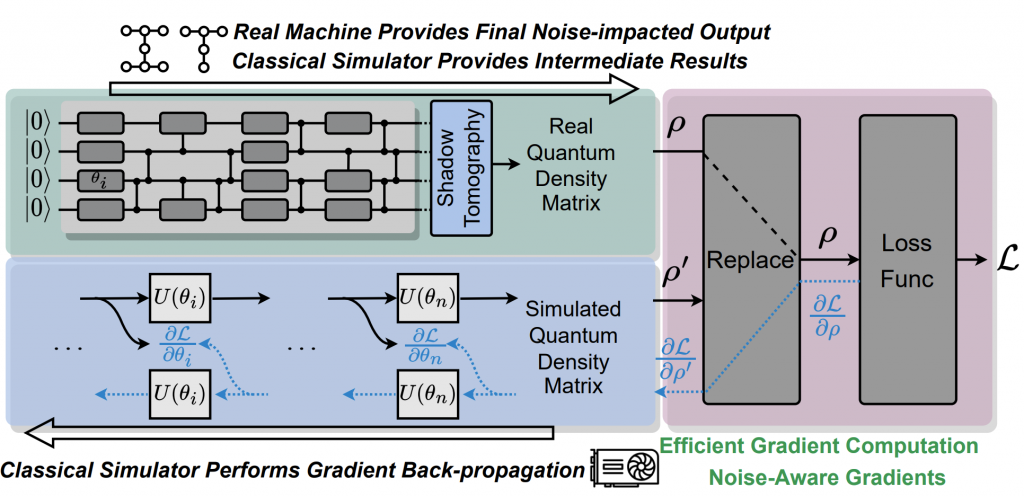
ICCAD’23 ML4Sci RobustState: Boosting Fidelity of Quantum State Preparation via Noise-Aware Variational Training
Hanrui Wang, Yilian Liu, Pengyu Liu, Jiaqi Gu, Zirui Li, Zhiding Liang, Jinglei Cheng, Yongshan Ding, Xuehai Qian, Yiyu Shi, David Z. Pan, Frederic T. Chong, Song Han
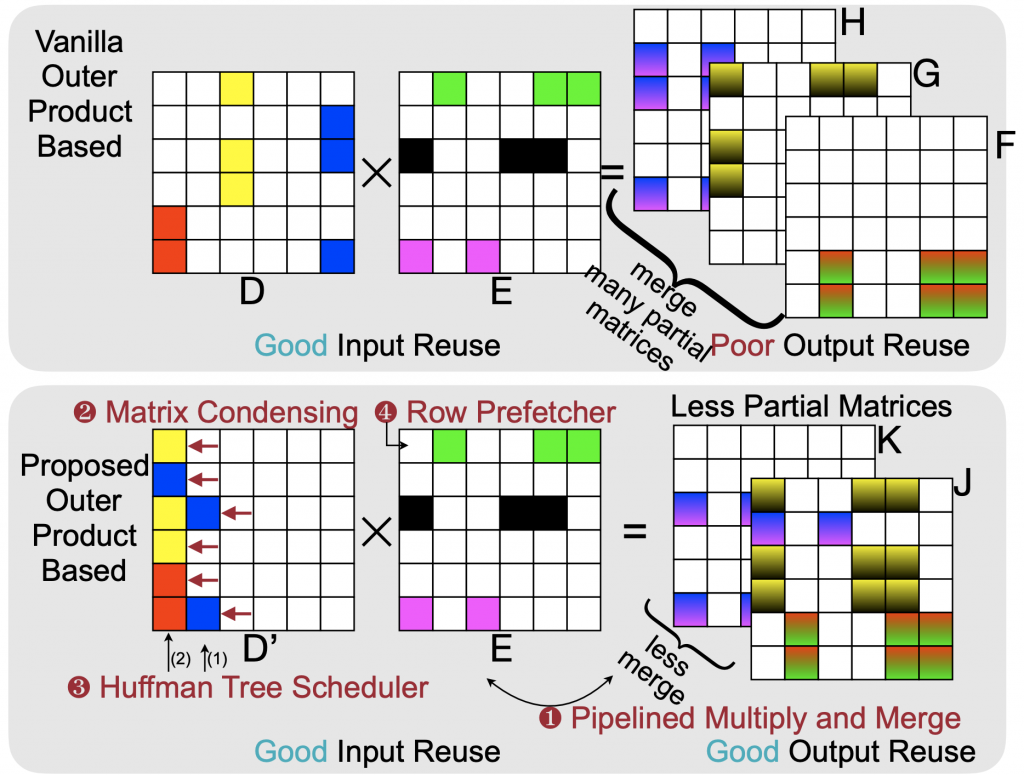
HPCA’20 SpArch: Efficient Architecture for Sparse Matrix Multiplication
Hanrui Wang*, Zhekai Zhang*, Song Han, William J. Dally (*Equal Contributions)
Paper / 2-min Intro / Intro / Talk / Slides / Project Page
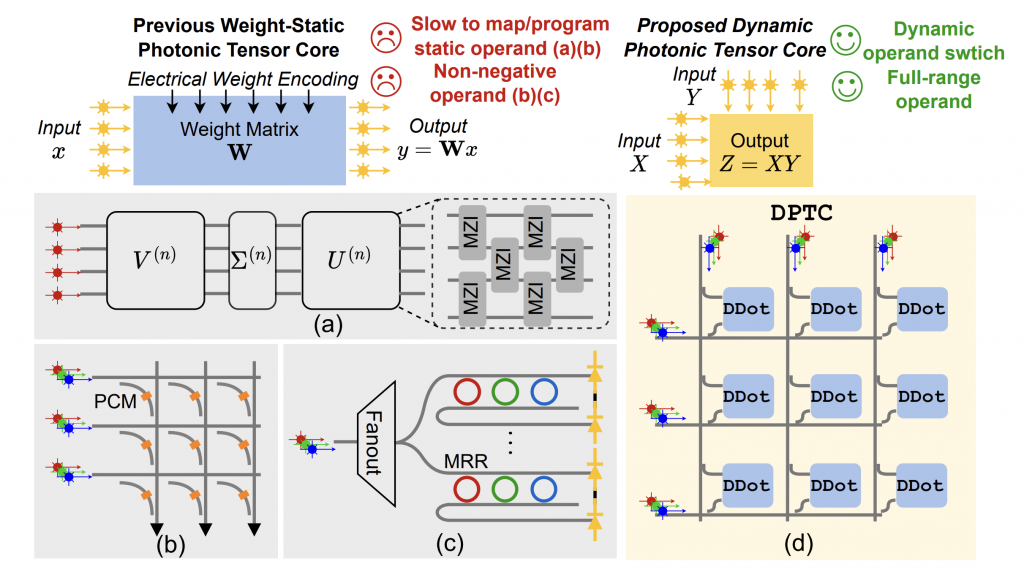
HPCA’24 DOTA: A Dynamically-Operated Photonic Tensor Core for Energy-Efficient Transformer Accelerator
Hanqing Zhu, Jiaqi Gu, Hanrui Wang, Zixuan Jiang, Zhekai Zhang, Rongxing Tang, Chenghao Feng, Song Han, Ray T. Chen, David Z. Pan
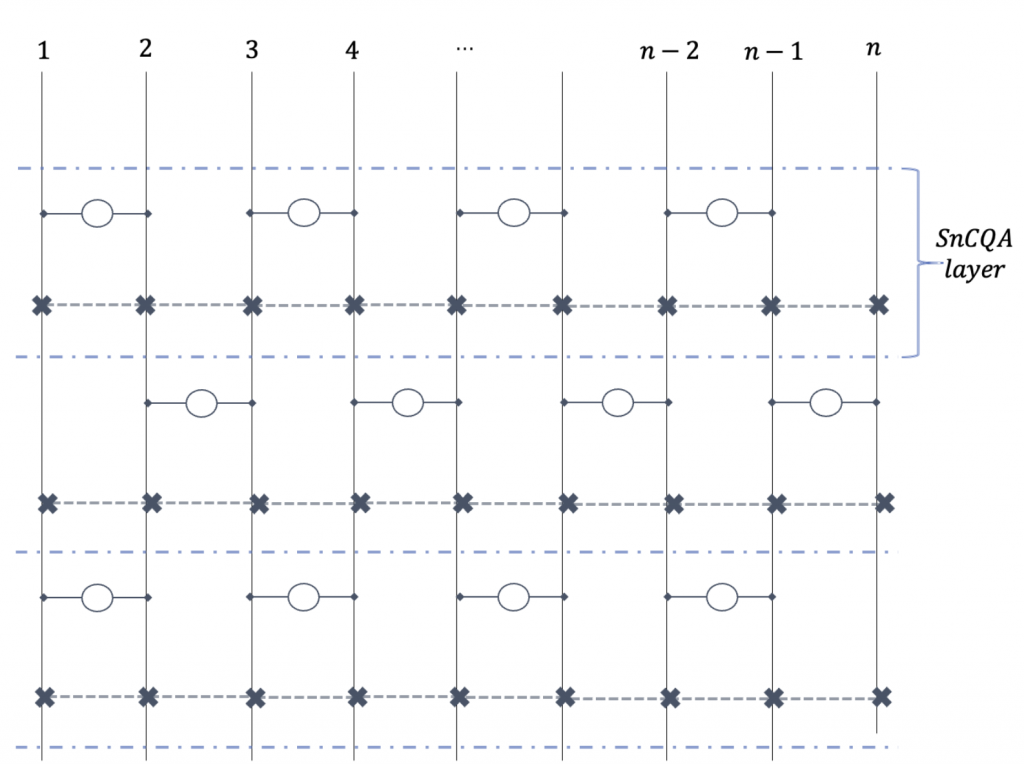
QCE’23 SnCQA: An hardware-efficient equivariant quantum convolutional circuit architecture
Han Zheng, Christopher Kang, Gokul Subramanian Ravi, Hanrui Wang, Kanav Setia, Frederic T. Chong, Junyu Liu
Best Paper Award
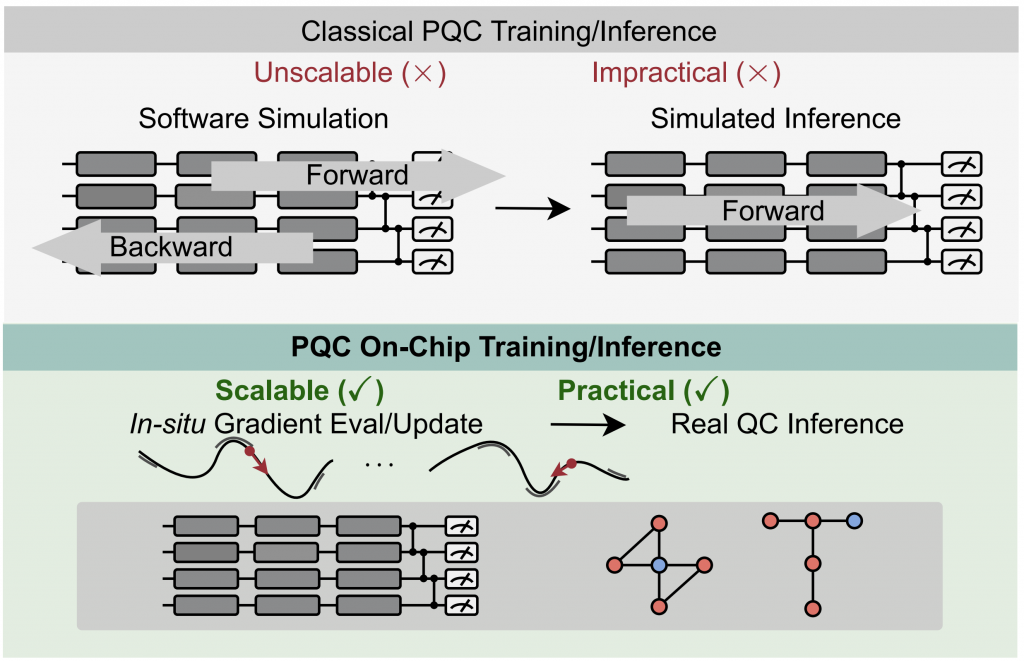
DAC’22 QOC: Quantum On-Chip Training with Parameter Shift and Gradient Pruning
Hanrui Wang, Zirui Li, Jiaqi Gu, Yongshan Ding, David Z. Pan, Song Han
Best Presentation Award at MIT MARC Conference
Paper / Code / Project Page
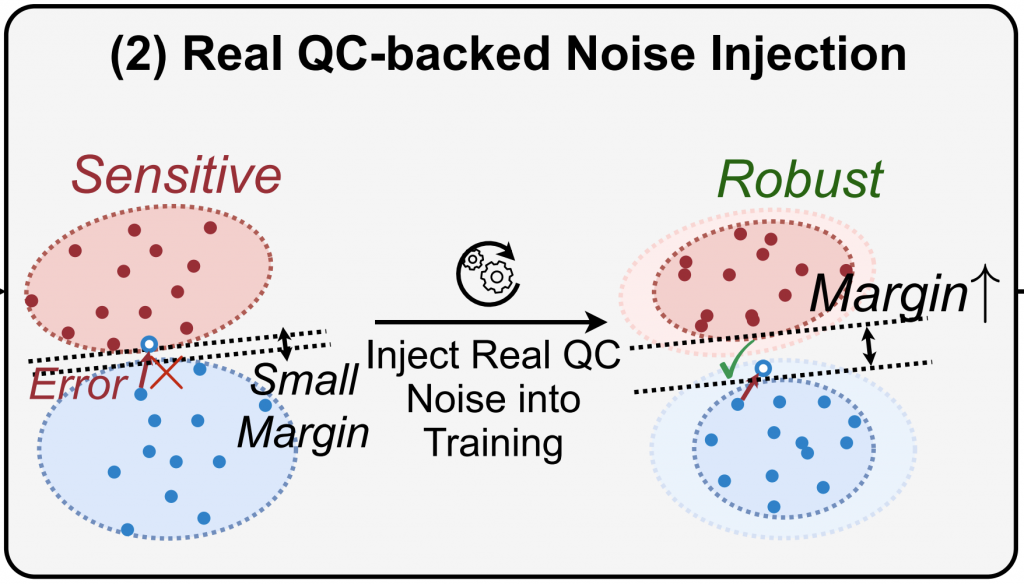
DAC’22 QuantumNAT: Quantum Noise-Aware Training with Noise Injection, Quantization and Normalization
Hanrui Wang, Jiaqi Gu, Yongshan Ding, Zirui Li, Frederic T. Chong, David Z. Pan, Song Han
Paper / Code / Project Page
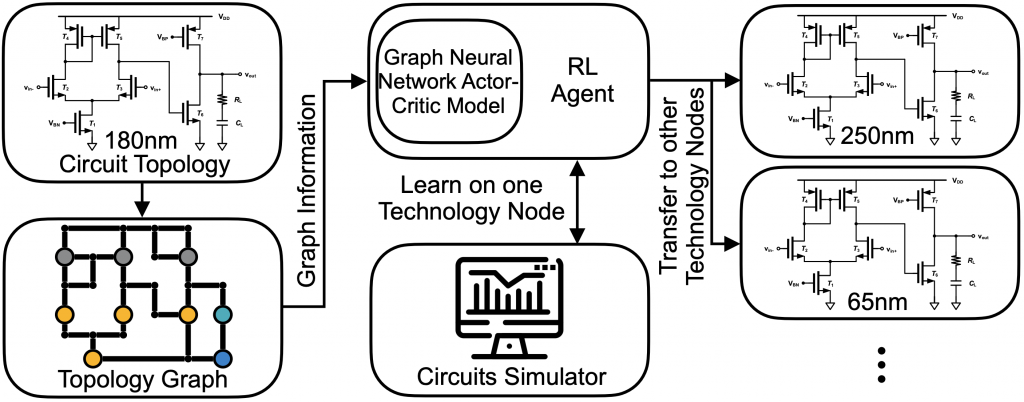
DAC’20 GCN-RL Circuit Designer: Transferable Transistor Sizing With Graph Neural Networks and Reinforcement Learning
Hanrui Wang, Kuan Wang, Jiacheng Yang, Linxiao Shen, Nan Sun, Hae-Seung Lee, Song Han
Best Presentation Award as Young Fellow, DAC 2022
Analog Devices Outstanding Student Designer Award
Paper / Slides / Poster / Video / Project Page
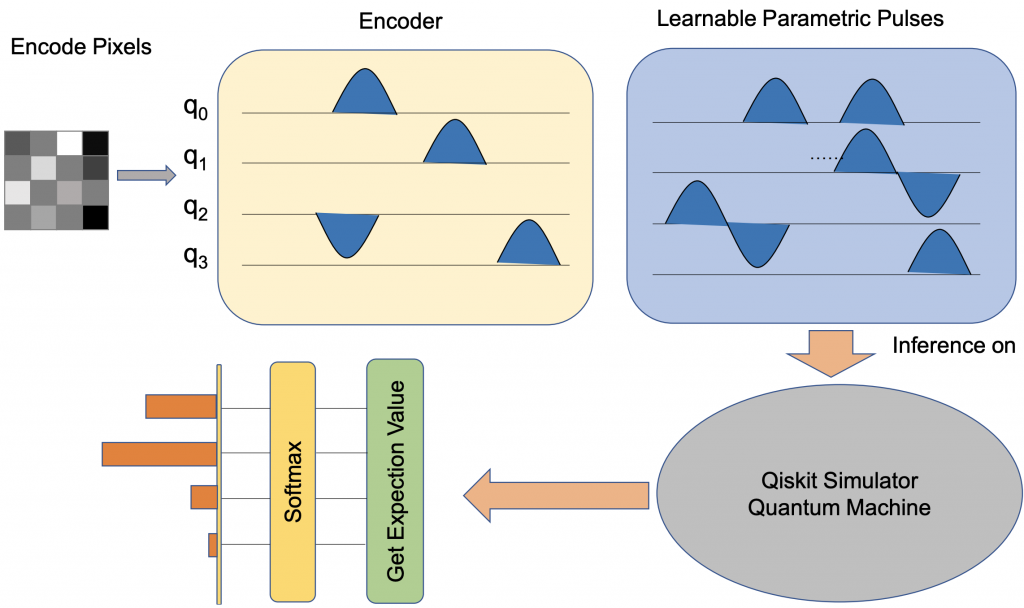
QCE’22 Variational Quantum Pulse Learning
Hanrui Wang*, Zhiding Liang*, Jinglei Cheng, Yongshan Ding, Hang Ren, Zhengqi Gao, Xuehai Qian, Song Han, Weiwen Jiang, Yiyu Shi
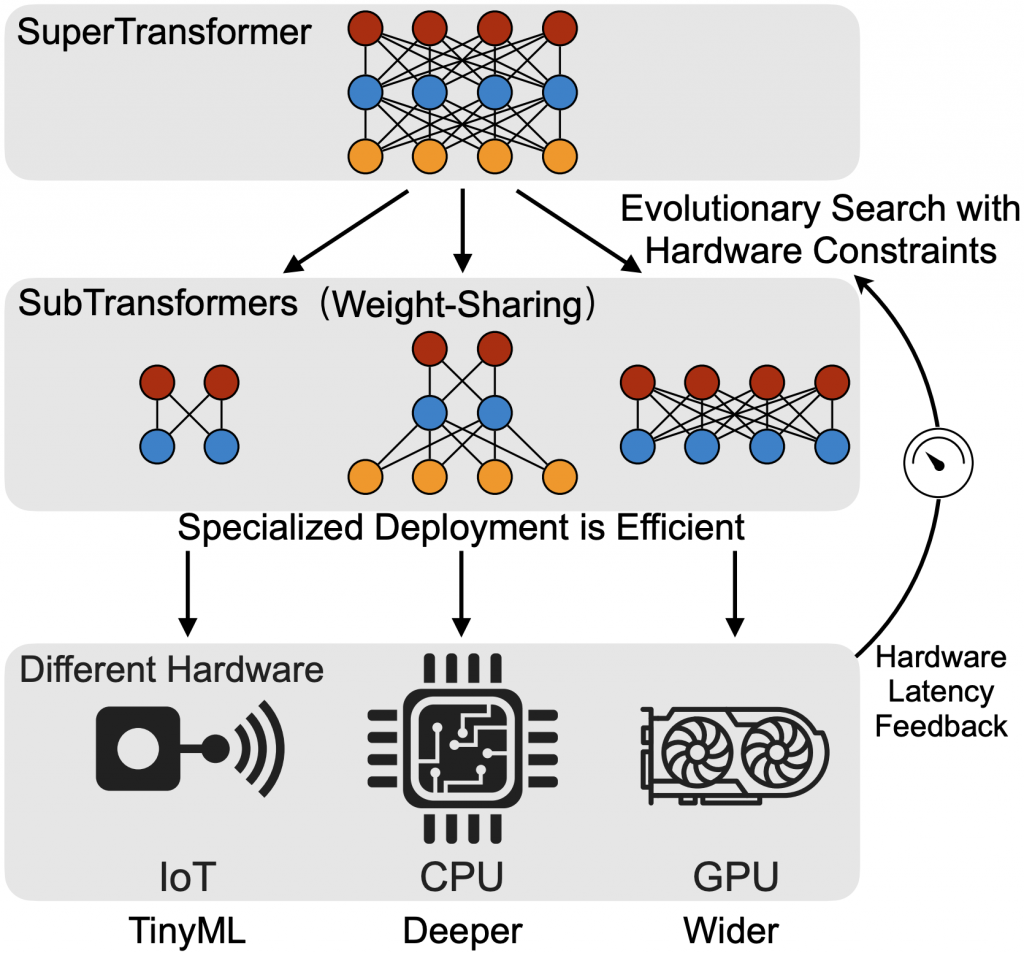
ACL’20 HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
Hanrui Wang, Zhanghao Wu, Zhijian Liu, Han Cai, Ligeng Zhu, Chuang Gan, Song Han
1st Place NeurIPS 2019 MicroNet efficient Language Model Competition
Paper / Slides / Video / Code / Project Page

ISLPED’23 A Fully-Integrated Energy-Scalable Transformer Accelerator Supporting Adaptive Model Configuration and Word Elimination for Language Understanding on Edge Devices
Zexi Ji*, Hanrui Wang*, Miaorong Wang, Win-San Khwa, Meng-Fan Chang, Song Han and Anantha P. Chandrakasan (*Equal Contributions)
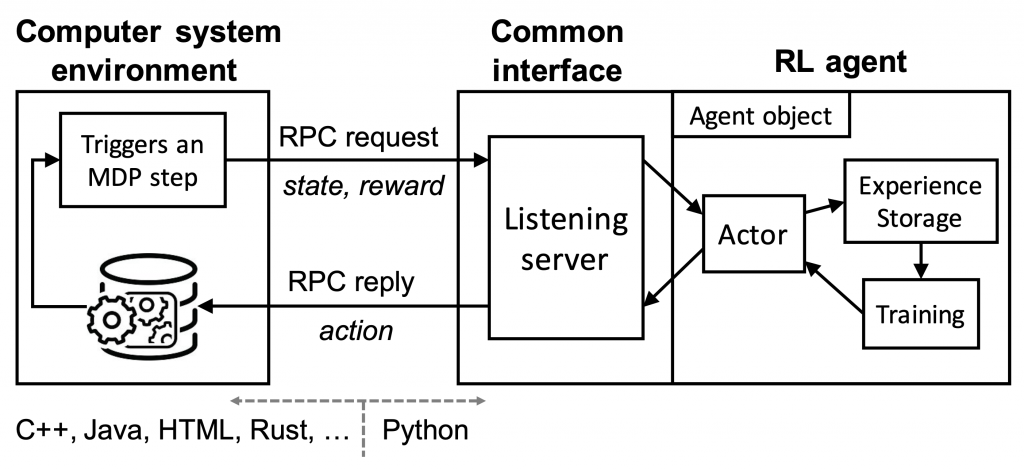
NeurIPS’18 Park: An Open Platform for Learning-Augmented Computer Systems
Hongzi Mao, Parimarjan Negi, Akshay Narayan, Hanrui Wang, Jiacheng Yang, et al
Best Paper Award, ICML RL4RL Workshop 2019
Paper / Code
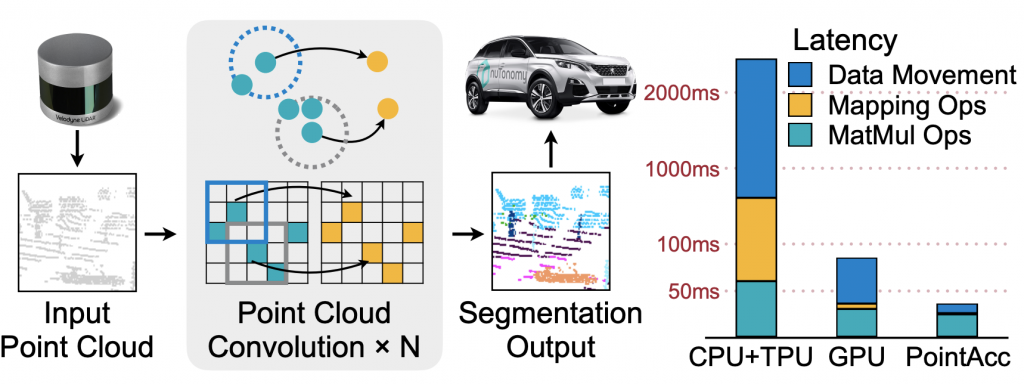
MICRO’21 PointAcc: Efficient Point Cloud Accelerator
Yujun Lin, Zhekai Zhang, Haotian Tang, Hanrui Wang, Song Han
Paper / Slides / Video / Short Video / Project Page
Recent Talks
Honors and Awards
- 2024 Rising Star of ISSCC 2024
- 2023 1st Place of ACM/IEEE Quantum Computing for Drug Discovery Challenge
- 2023 PhD Forum Attendee at MICRO 2023
- 2023 Best Paper Award at IEEE QCE 2023
- 2023 Best Demo Award at DAC 2023 University Demo
- 2023 PhD Forum Attendee at DAC 2023
- 2023 Rising Star in Machine Learning and Systems
- 2023 Best Poster Award at Athena Institute
- 2023 Best Pitch Award in MIT Microsystems Annual Research Conference
- 2022 1st Place in ACM Student Research Competition
- 2022 1/150 Place in ACM/IEEE TinyML Design Contest, memory size track
- 2022 NSF AI Institute Best Poster Award rank #1.
- 2022 DAC Young Fellowship
- 2021 Qualcomm Graduate Fellowship
- 2021 Baidu Graduate Fellowship
- 2021 Analog Devices Outstanding Student Designer Award
- 2021 Global Top 100 Chinese Rising Stars in AI Award
- 2020 Nvidia Graduate Fellowship Finalist
- 2020 DAC Young Fellow Best Presentation Award
- 2020 DAC Young Fellowship
- 2019 Champion of NeurIPS 2019 MicroNet efficient Language Model Competition
- 2019 Best Paper Award of ICML 2019 Reinforcement Learning for Real Life Workshop
- 2018 Bronze Medal in Kaggle TensorFlow Speech Recognition Challenge
- 2017 UCLA CSST Fellowship & CSST Best Research Award
- 2016 Chun-Tsung Research Fellowship
- 2015/16/17 China National Scholarship
Teaching
- QuCS “Quantum Computer Systems Lecture Series”
- Co-Instructor and Course Developer, MIT course, 6.5940 “TinyML and Efficient Deep Learning Computing”, 2023
- Organizer and Instructor, ISCA Tutorial on “TorchQuantum: A Fast Library for Parameterized Quantum Circuits”, 2023
- Teaching Assistant, MIT 6.812/6.825 “Hardware Architecture for Deep Learning”, 2020
- Guest Instructor, MIT 6.812/6.825 “Hardware Architecture for Deep Learning” on “Machine Learning Training”, 2022
- Co-Instructor and Course Developer, MIT new course, 6.S965 “TinyML and Efficient Deep Learning”, 2022
- Organizer and Instructor, ICCAD Tutorial on “TorchQuantum Case Study for Robust Quantum Circuits”, 2022
- Organizer and Instructor, QCE Tutorial on “TorchQuantum: A Fast Library for Parameterized Quantum Circuits”, 2022
- Organizer and Instructor, QCE Tutorial on “Parameterized Quantum Pulse and Its applications.”, 2023
- Grader, MIT 6.004 “Computation Structures”, 2020
- Teaching Assistant, Fudan University, “Game Theory”, 2017
Services
- Invited Reviewer for ICML, NeurIPS, ICLR, EMNLP, ACL, JMLR, IJCV, TCAS-II, TMLR, TODAES, TNNLS, TQC, MLR, ICITED, TASE, ADVCOMP, Pattern Recognition, FUZZ, IJCNN, JOSS, CEC, WCCI, ICECCME, ICECET
- External Review Committee for MLSys
- Session Chair for DAC 2022
- Web Chair for SOFC 2023
- TPC Member ICCAD 2023
© 2019-2023 Hanrui Wang